
생성형 AI의 지배력, 여전히 파라미터 수가 핵심일까?
2025년 하반기, 생성형 AI 시장은 여전히 빠르게 진화하고 있습니다. 다양한 기술 기업들이 초거대 언어 모델을 출시하면서, 파라미터 수는 다시 한번 주요 이슈로 부상했습니다. 본 글에서는 주요 AI 기업들의 모델 파라미터 수 변화와 그 흐름을 분석하고, 단순한 숫자 경쟁을 넘어서 성능과 효율성 중심으로 변화하는 흐름을 살펴봅니다.
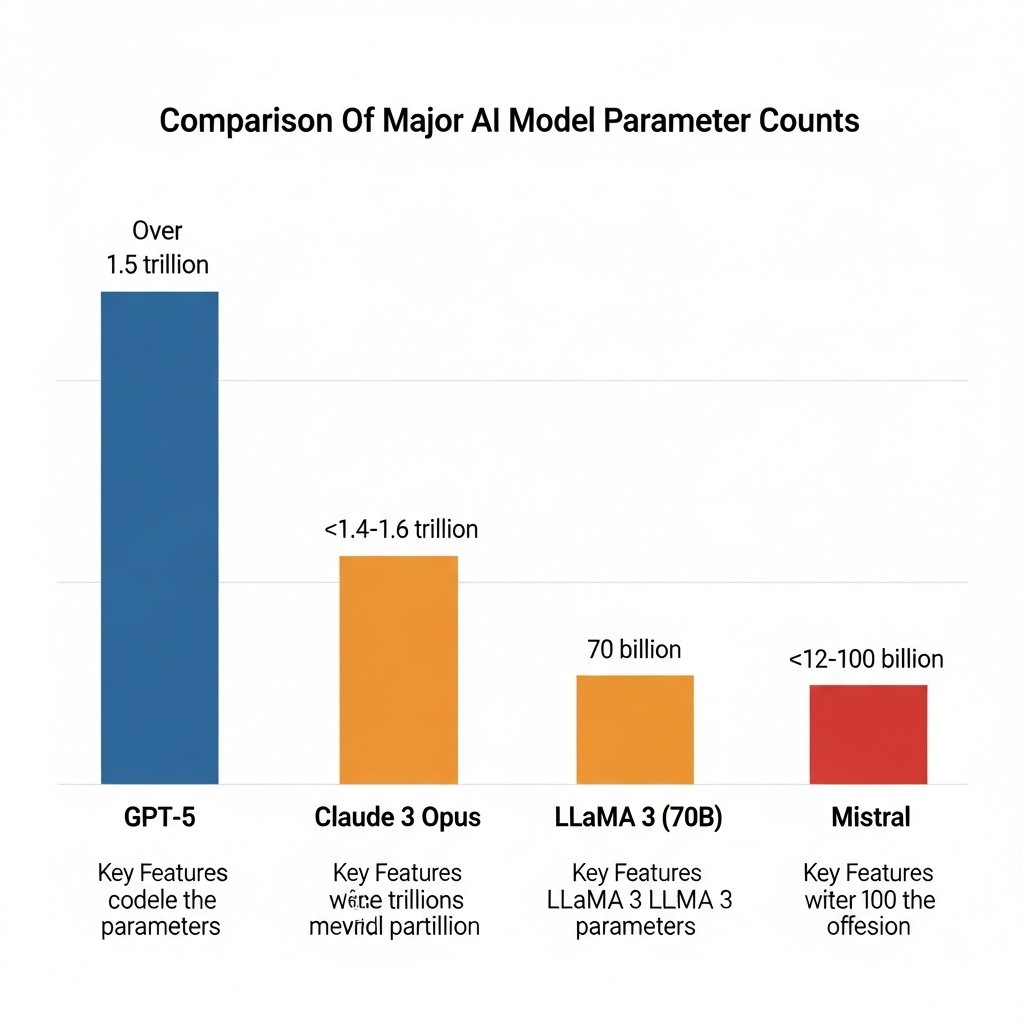
GPT-5와 Claude 3: 파라미터 비공개의 의미는?

GPT-5는 공식적으로 파라미터 수를 공개하지 않았지만, 업계에서는 1.5조 이상으로 추정하고 있습니다. 이는 GPT-4 대비 소폭 증가한 수준으로, 파라미터 확대보다는 최적화 기술에 초점을 맞췄다는 의미로 해석됩니다.
Anthropic의 Claude 3 Opus도 정확한 파라미터 수는 공개하지 않았지만, 여러 벤치마크에서 GPT-4를 능가하는 성능을 보이며 고성능 최적화의 중요성을 드러냈습니다.
Meta의 LLaMA 3: 400억·700억 파라미터 모델의 시장 반응
Meta는 LLaMA 3를 400억과 700억 파라미터 버전으로 출시했습니다.
상대적으로 경량 모델임에도 불구하고 실제 성능에서 높은 평가를 받았으며,
특히 오픈소스 커뮤니티에서 개발자와 연구자들의 큰 호응을 얻고 있습니다.
이러한 현상은 AI 모델 시장에서 “큰 모델이 무조건 우세하다”는 인식이 변화하고 있음을 보여줍니다.
파라미터 수와 성능의 관계, 여전히 유효한가?
과거에는 파라미터 수가 많을수록 성능이 좋다는 인식이 지배적이었습니다.
하지만 현재는 파인튜닝 기술, 프롬프트 최적화, 메모리 효율성 등
다양한 요인이 모델 품질에 영향을 미치며, 단순한 파라미터 수 증가만으로는 한계가 있다는 평가가 많아지고 있습니다.
주요 AI 모델 파라미터 수 비교표
| 모델명 | 파라미터 수(추정) | 주요 특징 |
| GPT-5 | 1.5조 이상 | 비공개, 성능 최적화 중심 |
| Claude 3 Opus | 약 1.4~1.6조 | 문해력 강화, 빠른 응답 속도 |
| LLaMA 3 (700억) | 700억 | 경량형, 효율적 구조 설계 |
| Mistral | 약 120억~1000억 | 모듈형 모델 구성 |
중국 기술 기업들, 여전히 파라미터 수 중심 전략 유지
Baidu, Tencent, Alibaba 등의 중국 기업들은
2조~3조 파라미터 규모의 모델을 앞세우며 여전히 초대형 모델 전략을 유지하고 있습니다.
그러나 실제 성능 면에서는 서구권 모델에 비해 일관성과 안전성에서 부족하다는 평가도 많아
“큰 모델 = 좋은 모델” 전략의 지속 가능성에 의문이 제기되고 있습니다.
파라미터 수 대신 '효율성 지표'로 중심 이동
OpenAI와 Google DeepMind 등은 최근 FLOPs(부동소수점 연산), 지연 시간, 토큰 처리량 등
효율성과 관련된 지표에 더 많은 비중을 두고 있습니다.
실제 현장에서 중요한 건 반응 속도와 처리량이며,
이는 곧 파라미터 중심 경쟁에서 탈피하는 흐름을 의미합니다.
기업별 모델 전략 요약 표
| 기업명 | 대표 모델 | 전략 방향 |
| OpenAI | GPT-5 | 최적화, 기능 다양화 |
| Anthropic | Claude 3 | 문해력 강화, 빠른 응답 |
| Meta | LLaMA 3 | 경량화, 오픈소스 지향 |
| Gemini 1.5 | 멀티모달, 효율 중심 설계 | |
| Alibaba | Qwen 시리즈 | 대규모 파라미터 중심 전략 |
앞으로 파라미터 경쟁은 어떤 의미를 가지게 될까?
2025년 하반기부터 생성형 AI 시장은 단순히 모델의 크기를 기준으로 평가하는 시대를 넘어
실제 사용자 경험, 응답 시간, 효율성 등 정성적 기준을 더 중요하게 고려하는 방향으로 재편되고 있습니다.
파라미터 수는 여전히 하나의 지표로 남겠지만, 그것만으로 성공을 보장할 수는 없습니다.
'재테크' 카테고리의 다른 글
| 무료 Mistral Small API 키 활용 완전 가이드 (0) | 2025.07.23 |
|---|---|
| Edge TPU vs GPU: 온디바이스 AI 가속기 성능 완전 비교 (0) | 2025.07.22 |
| AI가 만든 로고, Ideogram AI 로고 생성 툴 첫인상 (0) | 2025.07.21 |
| LangChain Agents vs CrewAI: 멀티 에이전트 효율 누가 앞서나? (1) | 2025.07.21 |
| PixVerse Comic Creator: 웹툰 제작 전 과정을 체험해봤습니다 (0) | 2025.07.20 |



