
LoRA와 QLoRA는 무엇이며 어떻게 다를까? 성능과 목적 중심으로 살펴보기
소형 언어모델(SLM)에 대한 수요가 증가함에 따라, 모델을 더 작고 효율적으로 만드는 기술이 주목받고 있습니다.
그중에서도 LoRA와 QLoRA는 대표적인 경량화 기법으로, 그 원리와 적용 방식에는 명확한 차이가 존재합니다.
이 글에서는 LoRA와 QLoRA의 개념, 구현 방식, 장단점을 비교하여
어떤 환경에 어떤 기법이 적합한지 알아보겠습니다.
LoRA란 무엇인가?
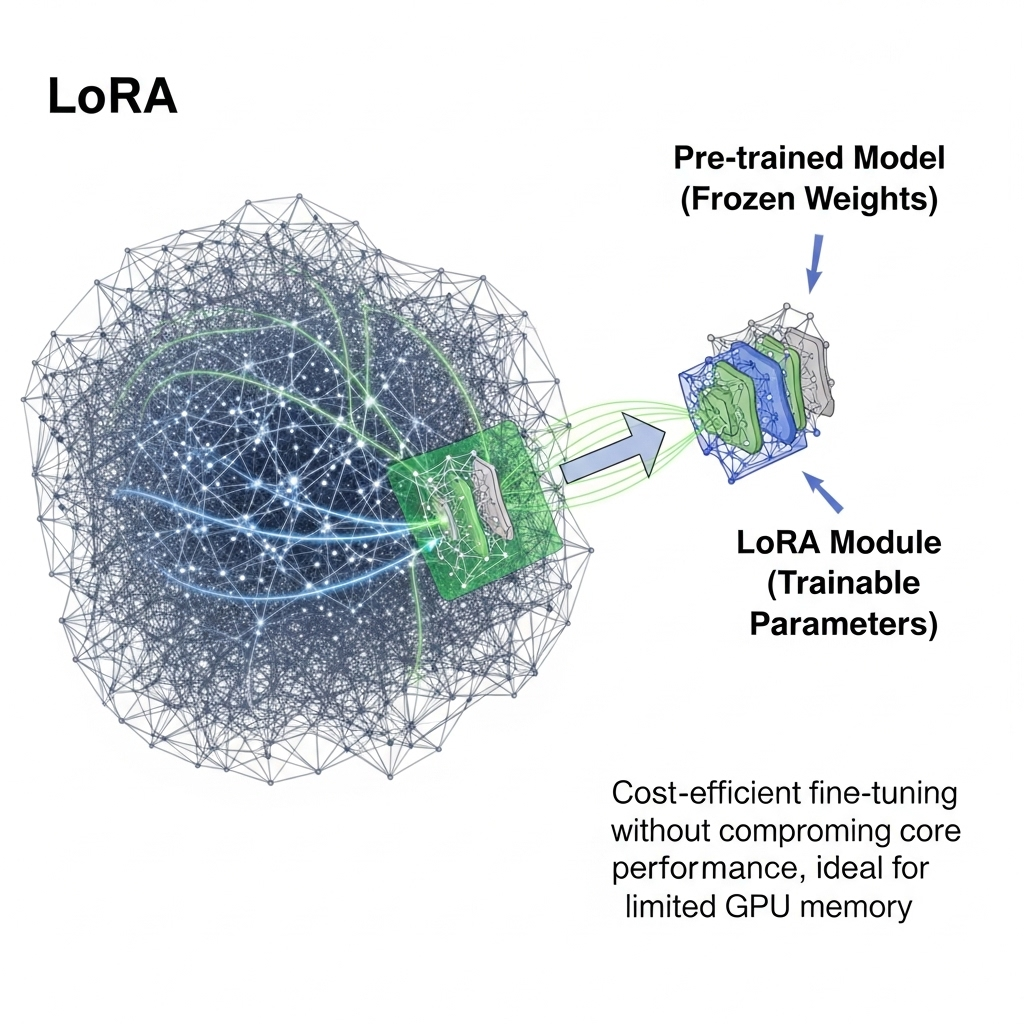
LoRA(Low-Rank Adaptation)는 사전 학습된 모델의 기존 가중치를 고정한 상태에서
일부 소량의 파라미터만 학습 가능한 형태로 추가하는 기법입니다.
이 방식은 모델의 핵심 성능을 유지하면서도 비용 효율적으로 미세 조정할 수 있게 해줍니다.
특히 GPU 메모리가 제한된 환경에서 효과적으로 활용될 수 있습니다.
QLoRA의 개념과 등장 배경
QLoRA는 "Quantized Low-Rank Adaptation"의 약자로,
LoRA 기법에 양자화(Quantization)를 결합한 방식입니다.
기존 LoRA의 장점에 더해, 모델 전체를 4비트로 양자화하여
메모리 절약과 학습 효율성을 극대화합니다.
즉, QLoRA는 극한의 메모리 효율성을 목표로 하는 LoRA의 진화형이라 할 수 있습니다.
LoRA와 QLoRA의 주요 차이점 요약
아래 표는 LoRA와 QLoRA의 핵심 차이점을 정리한 내용입니다.
| 구분 | LoRA | QLoRA |
| 방식 | 로우랭크 파라미터 추가 | 양자화 + 로우랭크 조정 |
| 메모리 효율성 | 보통 | 매우 높음 |
| 정밀도 | 일반적인 float32 수준 | 4비트로 약간의 정밀도 손실 가능 |
| 학습 속도 | 빠름 | 더 빠름 |
| 활용 목적 | 효율적인 파라미터 조정 | 초저비용, 고속 튜닝에 이상적 |
LoRA가 초기에 주목받은 이유는?
LoRA는 기존의 대규모 모델 구조를 변경하지 않으면서도
빠른 미세 조정이 가능하다는 점에서 연구자들과 산업계의 주목을 받았습니다.
수십억 개의 파라미터를 가진 모델을 수정 없이 활용하면서
제한된 환경에서도 학습 가능한 실용성이 핵심 강점이었습니다.
최근 트렌드에서 QLoRA가 주목받는 이유
모델 경량화에 대한 수요가 점점 더 정교해지면서,
단순한 미세 조정을 넘어선 효율성이 요구되고 있습니다.
이런 요구에 맞춰 QLoRA는 양자화 기술을 통해 메모리 사용을 최소화하고,
노트북에서도 수십억 개의 파라미터를 가진 모델을 학습할 수 있도록 지원합니다.
실제 적용 예시와 사용 환경

LoRA는 대체로 GPU 메모리가 충분한 환경에서
다양한 텍스트 관련 작업에 활용됩니다.
반면 QLoRA는 노트북, 클라우드, 로컬 서버 등
메모리 제약이 심한 환경에서 더욱 유리하며,
고속 프로토타입 제작이나 개인용 LLM 튜닝에 적합합니다.
어떤 환경에서 어떤 기법을 선택해야 할까?
아래 표는 LoRA와 QLoRA를 선택할 때 고려해야 할 기준을 정리한 것입니다.
| 환경 조건 | 추천 기법 |
| 메모리가 충분한 경우 | LoRA |
| 메모리 제약이 큰 경우 | QLoRA |
| 정밀도가 중요한 경우 | LoRA |
| 학습 속도 및 비용이 중요할 경우 | QLoRA |
| 초경량 튜닝이 필요한 경우 | QLoRA |
'재테크' 카테고리의 다른 글
| Zapier AI Actions로 SaaS 워크플로 자동화하는 가장 현실적인 방법 (1) | 2025.07.27 |
|---|---|
| HuggingFace Spaces vs Replicate: 어떤 플랫폼이 AI 모델 배포에 더 유리할까? (3) | 2025.07.27 |
| OpenAI Function Calling으로 구현하는 스마트 재고 관리 봇 만들기 (2) | 2025.07.26 |
| RAG 2.0, AI 장기 기억의 진화: 검색 기반 생성 기술의 핵심을 밝히다 (0) | 2025.07.25 |
| Gemini 1.5 Pro-Vision의 이미지 해설 능력, 어디까지 왔나? (2) | 2025.07.25 |



